Komputery / Komponenty PC
Instrukcja optymalizacji oprogramowania dla procesorów AMD Family 10h
Przewodnik po optymalizacji oprogramowania dla procesorów AMD Family 10h. Dowiedz się, jak poprawić wydajność kodu, wykorzystać instrukcje SIMD, zoptymalizować pamięć podręczną i zarządzanie pamięcią.
Spis treści
Obrazy z instrukcji
Kliknij obraz, aby powiększyćNajważniejsze informacje z instrukcji
Ten dokument to przewodnik dla programistów optymalizujących kod pod architekturę procesorów AMD Family 10h. Instrukcja zawiera szczegółowe zalecenia dotyczące pisania wydajnego kodu w językach C, C++ oraz asemblerze, wykorzystując specyficzne cechy mikroarchitektury AMD.
Optymalizacja kodu C/C++
Aby uzyskać najlepszą wydajność, należy zwrócić uwagę na:
- Deklaracje zmiennych: Używaj sufiksów 'f' dla liczb typu float.
- Wskaźniki vs Tablice: Preferuj notację tablicową, aby ułatwić kompilatorowi analizę aliasingu.
- Pętle: Stosuj całkowite rozwijanie pętli (loop unrolling) dla małych, stałych liczb iteracji.
- Warunki: Układaj operandy w wyrażeniach logicznych (&&, ||) tak, aby najszybciej kończyć ewaluację (short-circuiting).
Optymalizacja pamięci i pamięci podręcznej
Kluczowe aspekty zarządzania pamięcią:
- Wyrównanie danych: Dane powinny być naturalnie wyrównane do rozmiaru swojego typu.
- Store-to-Load Forwarding: Unikaj zależności typu zapis-odczyt, dopasowując rozmiary operacji.
- Write-Combining: Wykorzystuj bufory write-combining dla operacji zapisu do pamięci MMIO.
- Unikanie konfliktów: Dbaj o to, aby operacje ładowania nie powodowały konfliktów banków w pamięci podręcznej L1.
Optymalizacja instrukcji i szeregowania
Wskazówki dotyczące wydajności instrukcji:
- DirectPath vs VectorPath: Preferuj instrukcje DirectPath, które są dekodowane bezpośrednio w sprzęcie.
- Szeregowanie: Unikaj blokad generowania adresów (address-generation interlocks) poprzez odpowiednie szeregowanie instrukcji ładowania i zapisu.
- Instrukcje SIMD: Wykorzystuj SSE, SSE2, SSE3 i SSE4a do operacji zmiennoprzecinkowych i całkowitych, zamiast starszych instrukcji x87.
Rozważania wieloprocesorowe i wirtualizacja
W systemach wieloprocesorowych (ccNUMA) kluczowe jest:
- Lokalność danych: Utrzymywanie danych blisko wątku, który z nich korzysta.
- Unikanie False Sharing: Zapobieganie współdzieleniu linii pamięci podręcznej przez różne wątki.
- Wirtualizacja: Minimalizacja liczby przełączeń świata (world switches) w środowiskach wirtualnych poprzez optymalizację obsługi przerwań i konfigurację VMCB.
Praktyczna pomoc
Typowe problemy
Store-to-load forwarding stalls
Dopasuj rozmiary operacji ładowania i zapisu, unikaj niepotrzebnych zależności między zapisem a odczytem tego samego adresu.
Branch misprediction
Używaj instrukcji CMOVxx zamiast skoków warunkowych, gdzie to możliwe, aby uniknąć kosztownych błędów przewidywania skoków.
Cache bank conflicts
Wyrównuj dane do granic 16-bajtowych i unikaj jednoczesnego dostępu do konfliktujących banków pamięci L1.
Nieefektywne użycie instrukcji
Preferuj instrukcje DirectPath zamiast VectorPath, sprawdzając latencje w załączonych tabelach.
Przed użyciem
- Sprawdź, czy pętle są w pełni rozwinięte (unrolling) dla małych, stałych liczb iteracji.
- Upewnij się, że dane są wyrównane do granic 16-bajtowych.
- Używaj instrukcji DirectPath zamiast VectorPath.
- Unikaj zależności typu store-to-load.
- Stosuj instrukcje SIMD (SSE/SSE2/SSE3) zamiast x87 dla operacji zmiennoprzecinkowych.
- W systemach wieloprocesorowych dbaj o lokalność danych (ccNUMA).
Parametry w praktyce
- Write-Combining
- Technika łączenia wielu zapisów do pamięci w jeden cykl zapisu, redukująca obciążenie magistrali.
Ilustracje i schematy
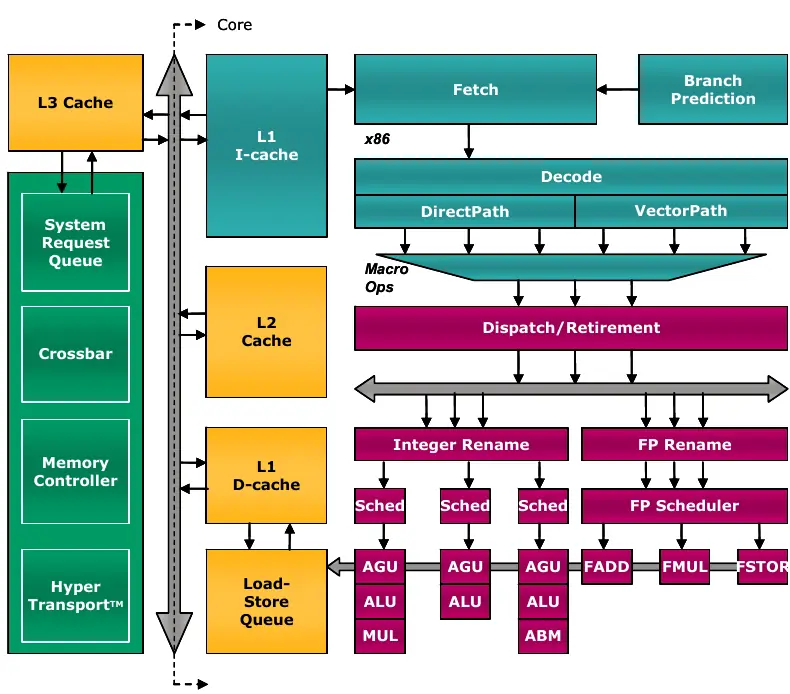
- Strona 242: Schemat blokowy procesora AMD Family 10h, pokazujący jednostki wykonawcze, pamięci podręczne i kolejki.
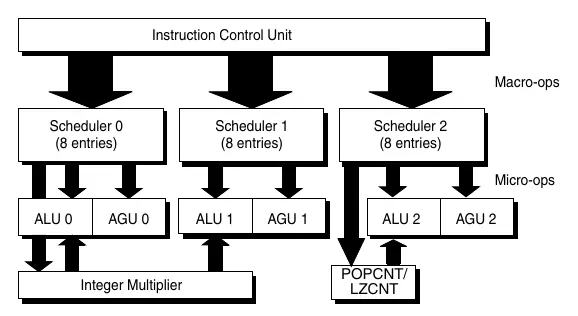
- Strona 247: Schemat potoku wykonawczego liczb całkowitych (Integer Execution Pipeline).
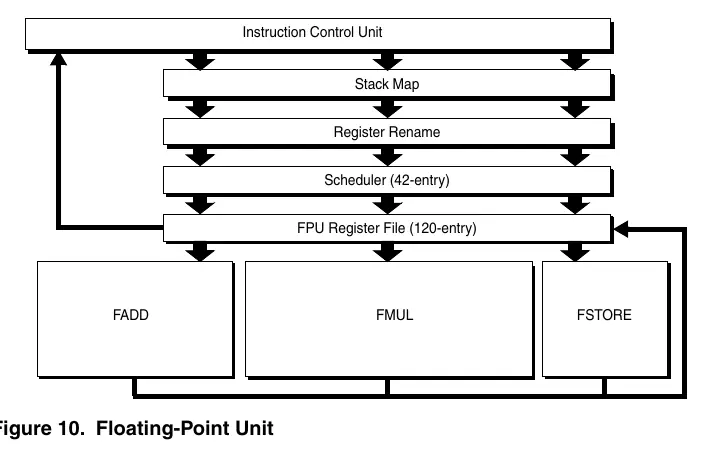
- Strona 249: Schemat jednostki zmiennoprzecinkowej (Floating-Point Unit).
Zgodność modelu
- Instrukcja dotyczy procesorów AMD Family 10h.
- Wiele optymalizacji jest specyficznych dla trybu 32-bitowego lub 64-bitowego.

Autor opracowania
Marek Zieliński
Redaktor instrukcji technicznych
Specjalizuje się w dokumentacji urządzeń domowych, elektroniki i narzędzi. Dba o jasny opis najważniejszych funkcji oraz praktyczne wskazówki dla użytkownika.