Komputery / Komponenty PC
Przewodnik optymalizacji oprogramowania dla procesorów AMD Family 10h
Szybki przewodnik po optymalizacji oprogramowania dla procesorów AMD Family 10h. Dowiedz się, jak poprawić wydajność kodu C/C++, zoptymalizować instrukcje 64-bitowe, pamięć podręczną, gałęzie i operacje SIMD.
Spis treści
Obrazy z instrukcji
Kliknij obraz, aby powiększyćNajważniejsze informacje z instrukcji
Ten przewodnik zawiera techniki optymalizacji oprogramowania dla procesorów AMD Family 10h. Skupia się na poprawie wydajności kodu C/C++, optymalizacji instrukcji 64-bitowych, zarządzaniu pamięcią podręczną, optymalizacji gałęzi (branching) oraz wykorzystaniu instrukcji SIMD i x87.
Optymalizacja kodu C i C++
Wskazówki dotyczące pisania wydajnego kodu źródłowego:
- Używaj notacji tablicowej zamiast wskaźnikowej, aby ułatwić optymalizację kompilatorowi.
- Całkowicie rozwijaj małe pętle (loop unrolling).
- Używaj kwalifikatora const dla obiektów, które nie zmieniają wartości.
- Sortuj i wypełniaj struktury dla naturalnego wyrównania danych.
Optymalizacja 64-bitowa
Techniki dla oprogramowania 64-bitowego:
- Używaj rejestrów 64-bitowych do arytmetyki 64-bitowej.
- Używaj instrukcji 128-bitowych (SSE) zamiast x87 dla operacji zmiennoprzecinkowych.
- Używaj rejestrów 32-bitowych (EAX-ESI) dla małych liczb całkowitych, aby uniknąć prefiksu REX.
Optymalizacja pamięci podręcznej i pamięci
Kluczowe zasady zarządzania pamięcią:
- Unikaj niedopasowań rozmiaru pamięci przy operacjach store/load.
- Używaj instrukcji prefetch i streaming, aby ukryć opóźnienia pamięci.
- Unikaj konfliktów banków pamięci podręcznej L1.
- Wyrównuj dane do granic 16-bajtowych dla operacji SIMD.
Optymalizacja gałęzi i planowania
Techniki poprawy przewidywania gałęzi:
- Wyrównuj cele gałęzi do granic 32-bajtowych.
- Unikaj instrukcji LOOP.
- Używaj instrukcji CMOVxx zamiast gałęzi warunkowych, gdzie to możliwe.
- Unikaj gałęzi zależnych od losowych danych.
Optymalizacja SIMD i x87
Wykorzystanie instrukcji SIMD (SSE, SSE2, SSE3, SSE4a) jest zalecane dla operacji zmiennoprzecinkowych. Unikaj instrukcji x87, jeśli to możliwe, ze względu na ich niższą wydajność i ograniczenia rejestrów.
Praktyczna pomoc
Typowe problemy
Niedopasowanie rozmiaru pamięci przy operacjach store/load
Utrzymuj spójne rozmiary operandów dla operacji load i store. Używaj rozmiarów doubleword, quadword lub 128-bitowych.
Konflikty banków pamięci podręcznej L1
Paruj operacje ładowania (loads), które nie powodują konfliktów banków w pamięci podręcznej L1.
Zbyt duża liczba gałęzi warunkowych
Używaj instrukcji CMOVxx do symulacji ruchów warunkowych w kodzie SSE/MMX.
Przed użyciem
- Sprawdź, czy kod jest wyrównany do granic 16-bajtowych dla operacji SIMD.
- Upewnij się, że używasz instrukcji 128-bitowych zamiast x87 dla operacji zmiennoprzecinkowych.
- Zweryfikuj, czy pętle są odpowiednio rozwinięte (loop unrolling).
- Sprawdź, czy używasz instrukcji DirectPath zamiast VectorPath.
Parametry w praktyce
- L1 Cache Line
- Rozmiar linii pamięci podręcznej wynosi 64 bajty.
Ilustracje i schematy
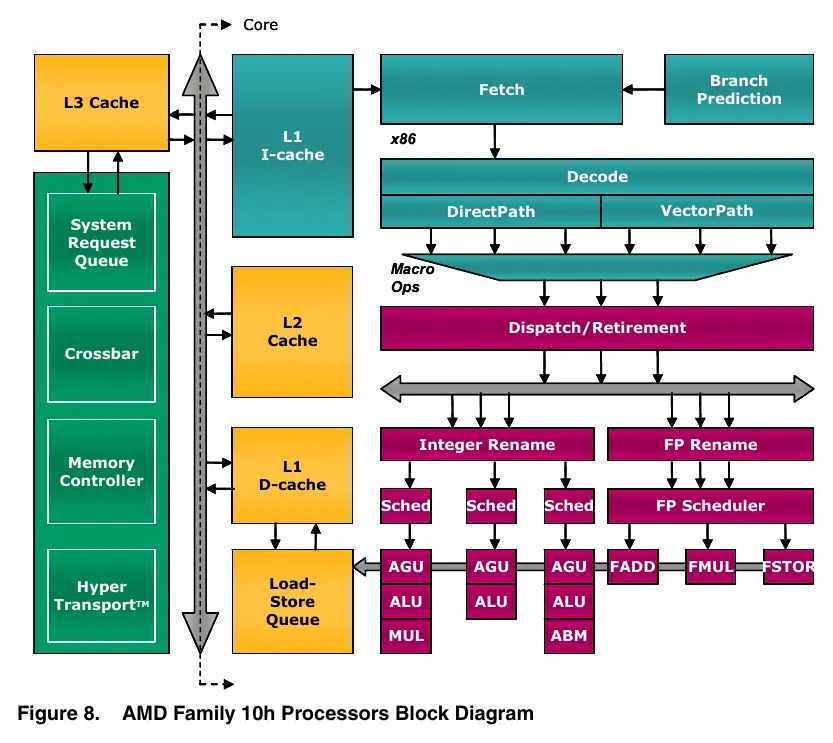
- Rysunek 8: Schemat blokowy procesora AMD Family 10h.
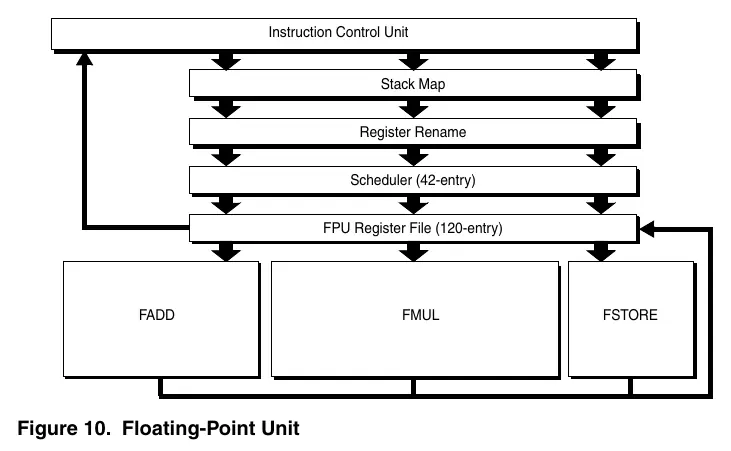
- Rysunek 10: Schemat przepływu danych przez jednostkę zmiennoprzecinkową (FPU).
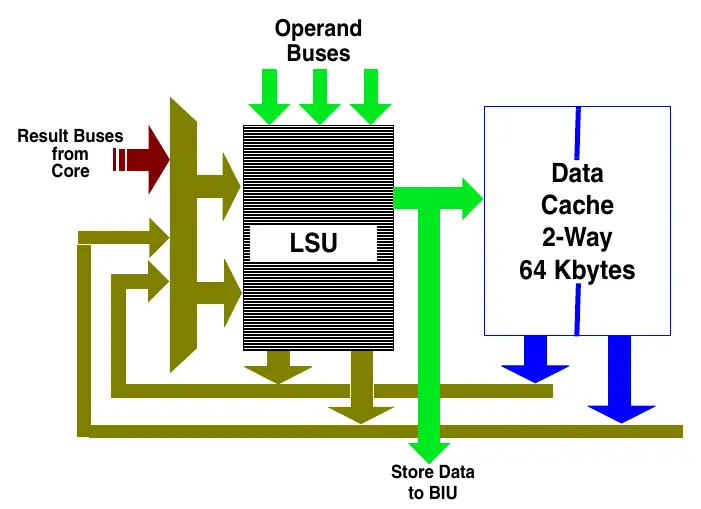
- Rysunek 11: Schemat jednostki Load-Store (LSU).
Zgodność modelu
- Optymalizacje opisane w przewodniku dotyczą procesorów AMD Family 10h.
- Niektóre optymalizacje 64-bitowe mają zastosowanie tylko w trybie 64-bitowym.

Autor opracowania
Marek Zieliński
Redaktor instrukcji technicznych
Specjalizuje się w dokumentacji urządzeń domowych, elektroniki i narzędzi. Dba o jasny opis najważniejszych funkcji oraz praktyczne wskazówki dla użytkownika.